
So here’s the thing. Most articles about Copy-on-Write and Merge-on-Read basically stop at “CoW is faster for reads, MoR is faster for writes.” And yeah, that’s technically true. But if that’s all you take away from this, you’re going to make some very expensive architectural mistakes, probably six months after you deploy and suddenly can’t figure out why your cloud bill doubled.

The real story is a lot more interesting. Because the choice between CoW and MoR doesn’t just affect your query speeds in isolation. It shapes your compute costs, your GDPR compliance posture, your operational overhead, and how well your entire data platform holds up under sustained production load.
So we’re going to dig into all of it. The mechanics, the write amplification math, the compaction strategies, the deletion vector evolution, the GDPR implications, and the actual decision framework you need. By the end of this, you’ll have a clear mental model for when to use each approach, and why the sharpest data engineering teams in 2026 aren’t treating this as a binary choice anymore.
Let’s get into it.
Key Takeaways
- CoW rewrites entire Parquet files on every update, fast reads, expensive writes
- MoR appends changes to delta logs or deletion vectors, fast writes, read overhead without compaction
- The RUM Conjecture proves no system can optimize read speed, write speed, and storage efficiency simultaneously
- Deletion vectors (Iceberg v3, Delta Lake) are the modern MoR standard, compact bitmaps replace scattered delete files
- Compaction is not optional maintenance, it’s the mechanism that makes MoR architecturally survivable
- Use MoR at the Bronze ingestion layer, hybrid at Silver, CoW or compacted MoR at Gold
- Standard MoR soft-deletes are not GDPR-compliant, hard-delete workflows are required for PII
- Post-compaction, MoR and CoW read performance becomes identical
The Core Problem: Why You Can’t Just Edit a Parquet File
Okay, so let’s start with the fundamental problem, because understanding why CoW and MoR exist in the first place makes everything else click.

Modern data lakehouses, whether you’re using Apache Iceberg, Delta Lake, or Apache Hudi, store data in columnar file formats like Parquet or ORC. These formats are incredible for analytical queries. They compress efficiently, they allow column pruning, they support predicate pushdown. The performance gains compared to row-based formats are massive.
But here’s the catch. Parquet files are physically immutable. You cannot edit a record inside a Parquet file the way you’d update a row in a PostgreSQL table. There’s no in-place update mechanism. The file is written once, and that’s it.
So what happens when you need to update or delete a record? You’ve got two conceptual options.
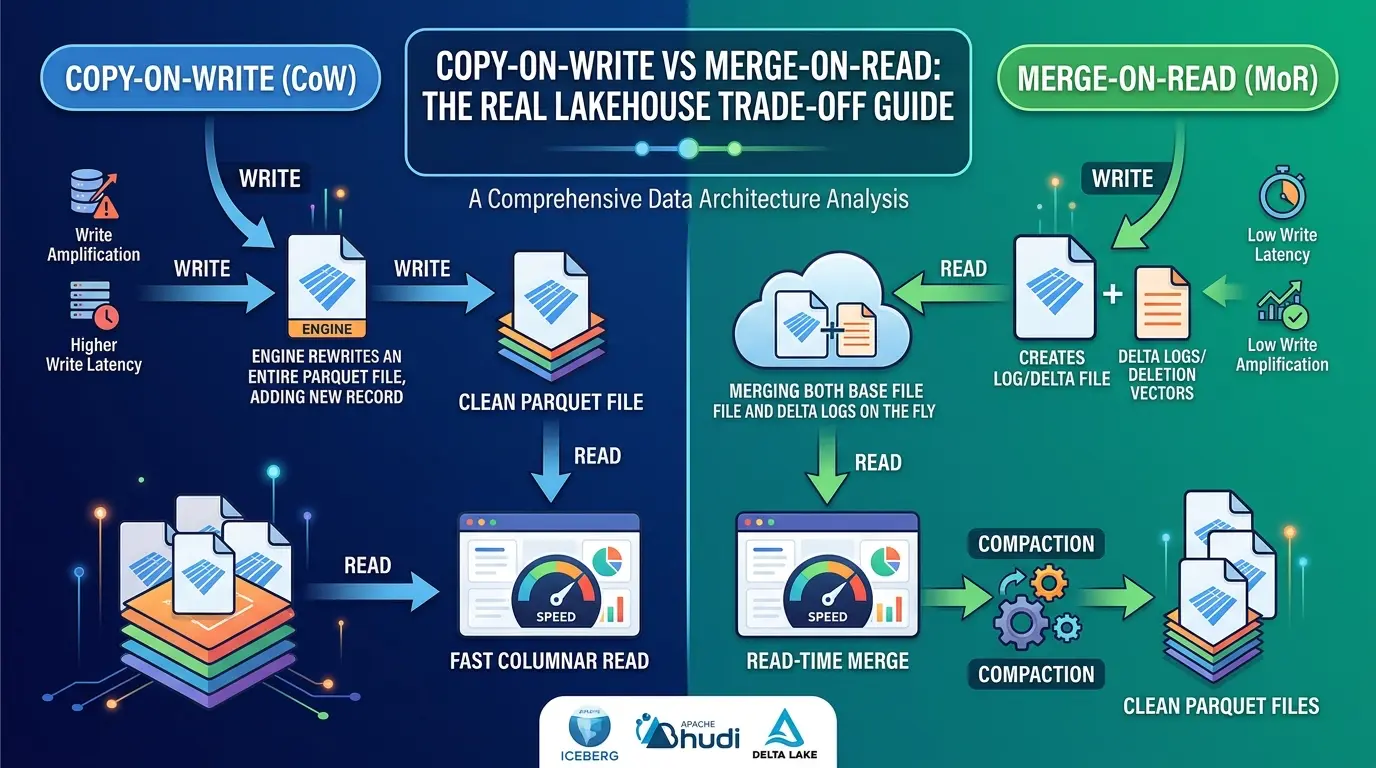
- Option one: Rewrite the entire affected file with the change applied. That’s Copy-on-Write.
- Option two: Record the change separately and merge it at read time. That’s Merge-on-Read.
Both approaches are solving the same fundamental problem. The difference is when you pay the reconciliation cost. CoW pays it at write time. MoR defers it to reading time. That’s the core insight that everything else builds on.
Section takeaway: The immutability of Parquet forces every lakehouse format to choose between paying the merge cost at write time (CoW) or at read time (MoR). There’s no free lunch.
The RUM Conjecture: Why You Can Never Win on All Three Fronts
Before we go deeper, we need to talk about the theoretical reason these trade-offs exist. It’s called the RUM Conjecture, and it’s the academic foundation that governs all of this.

The conjecture states that a storage system can optimize for at most two of three dimensions simultaneously:
- R: Read performance
- U: Update (write) performance
- M: Memory and storage overhead
You simply cannot win on all three. Every design choice is a deliberate sacrifice of one dimension to improve the other two.
CoW makes the trade-off explicit: it optimizes for read performance and memory efficiency at the expense of update performance. MoR does the opposite, it optimizes for update throughput, accepting higher read overhead and more complex storage management.
Understanding this means you stop looking for the “best” strategy and start looking for the right strategy for your specific workload. And that’s a very different question.
| Architectural Dimension | Copy-on-Write (CoW) | Merge-on-Read (MoR) |
|---|---|---|
| Write Latency | High — full file rewrite | Low — incremental delta logging |
| Query Latency | Low — direct columnar read | Higher — read-time merge overhead |
| Write Amplification | High — WAF scales with update density | Low — only changes are appended |
| Read Amplification | Minimal — pre-materialized files | Higher — multiple delta files parsed |
| Consistency Profile | Strong, write-time atomicity | Eventual (prior to compaction) |
| Best For | BI dashboards, infrequent updates | CDC, streaming, high-update ingestion |
Copy-on-Write: The “Pay Now, Read Fast Later” Strategy

How CoW Actually Works
So the idea with Copy-on-Write is conceptually straightforward. When you execute an update or delete, the query engine identifies which Parquet files contain the affected records using partition metadata or indexing structures. It reads those entire files into memory, applies the changes, and writes completely new versions of those files back to object storage.
The old files get marked as obsolete in the transaction log, and the new files become the active version for subsequent queries.
That’s it. Clean, atomic, and, when you later go to query the table, you’re reading perfectly clean, pre-materialized Parquet files with zero reconciliation overhead. The Apache Iceberg documentation on row-level operations identifies CoW as the default precisely because this behavior delivers the best analytical read experience out of the box.
The beauty of CoW is that reads are completely unencumbered. Your query engine just scans files. No metadata gymnastics, no delta log merging, no conditional row filtering. It’s as fast as it gets.
The Write Amplification Problem
Here’s where CoW gets expensive. The cost is formally expressed through the Write Amplification Factor (WAF), the ratio of physical bytes written to storage versus the logical bytes of the actual update payload.
Write Amplification Factor
A WAF of 1 means every byte written was a byte changed. A WAF of 100,000 means you wrote 100,000× more data than you actually modified.
🧮 Interactive WAF Calculator
Enter your Parquet file size and update payload to see your actual write amplification.
Think about what this means concretely. If you update a single 1 KB record inside a 100 MB Parquet file, the engine physically writes 100 MB to apply a 1 KB change. That's a WAF of 100,000x. For a single operation, that's annoying but acceptable. For a streaming CDC pipeline running every 5 minutes? It becomes economically catastrophic.
And it compounds. Four successive micro-batch updates each touching 10% of records in a 100 MB file generate five separate 100 MB files to disk, 500 MB of physical writes, before any cleanup processes remove the obsolete versions. That causes severe write-side latency spikes and excessive compute costs at scale.
When CoW Is Actually the Right Choice
Despite those write costs, CoW is genuinely excellent for specific workloads. The key question is simple: how often are records actually updated after they're written?
For append-only event streams, application logs, clickstreams, IoT telemetry, records are written once and never modified. CoW tables avoid rewrite costs entirely here because there are no updates to trigger rewrites, and downstream analytical engines get clean, unobstructed Parquet scans.
For BI reporting tables that receive scheduled batch updates on a predictable cadence, like an orders table refreshed every 15 minutes with corrections or refunds, CoW makes perfect sense. You accept the write latency during the ingest window, and your dashboards get fast columnar reads the rest of the time.
Section takeaway: CoW is highly efficient when updates are rare. The write cost is a one-time penalty, and the read dividend is permanent. It becomes prohibitively expensive only when update frequency is high relative to record density.
Merge-on-Read: The "Write Fast, Pay Later" Strategy

How MoR Works in Apache Hudi
So the idea with Merge-on-Read is fundamentally about doing less work at write time. Instead of rewriting the whole Parquet file, you just record what changed and attach it to the original.
In Apache Hudi, the architecture organizes data into logical "File Groups." Each File Group contains a single base Parquet file representing the last compacted snapshot, plus a series of append-only delta log files written in the row-based Avro format.
Hudi routes update operations directly to those log files using the HoodieAppendHandle class, it locates the target partition and file ID, dynamically creates log files, and appends changes without touching the underlying base Parquet file.
At query time, Hudi gives you two paths. Snapshot queries read the base Parquet files and associated Avro logs simultaneously, merging them in memory to reconstruct current record states. Read-Optimized (RO) queries scan only the base Parquet files, skipping the unmerged logs entirely, you trade data freshness for query speed. That granular control is really useful when you have consumers with different latency tolerances reading the same table.
The Read Amplification Reality
The downside of MoR is real and you shouldn't underestimate it. Every read must load the base file and all the associated delta logs or delete files, merge them in memory, and filter out deleted rows. As updates accumulate without compaction, this overhead compounds, gradually, not catastrophically.
Here's the performance data from a 100-million-row synthetic dataset comparing CoW and MoR configurations across various operations:
| Operation | CoW (Deletion Vectors Disabled) | MoR (Deletion Vectors Enabled) | Performance Difference |
|---|---|---|---|
| Single row delete | Slow — full Parquet rewrite | Extremely fast — tiny .bin file | ~8x faster |
| 33% row delete | Slow — heavy write amplification | Fast — compressed bitmaps | ~2.5x faster |
| Update (8% of rows) | Slow — rewrites impacted files | Moderate — soft-delete + new write | Faster (less pronounced) |
| OPTIMIZE (compaction) | High cluster usage | Highly efficient | ~2x faster |
| VACUUM | Slow — processes large files | Highly efficient | ~1.7x faster |
| Read (uncompacted, 53% modified) | Baseline optimized | Significant bitmap parsing overhead | ~2.3x slower |
| Read (uncompacted, 5% modified) | Baseline optimized | Moderate overhead | ~1.5x slower |
| Read (post-compaction) | Baseline optimized | DVs purged, clean files | ✅ Identical performance |
That last row is really important. After running OPTIMIZE compaction, read performance becomes identical to CoW. The deletion vector metadata is purged, and readers access clean, fully consolidated Parquet files. So the read penalty is real, but it's not permanent, it's a function of compaction cadence.
Section takeaway: MoR is incredibly efficient for write-heavy workloads, but read overhead is real and compounds over time. Compaction converts MoR's read cost back to CoW parity, making compaction design inseparable from MoR deployment design.
Delete Files in Apache Iceberg: Position Deletes vs Equality Deletes
Let's zoom into Apache Iceberg specifically, because it handles MoR through a particularly interesting mechanism that's worth understanding in detail. There are two types of delete files in Iceberg v2, and the difference between them really matters.

Position deletes record the exact file path and row index of each deleted record. Basically, you're saying "in this specific Parquet file, row 10 is deleted." The write side is moderately fast, you don't rewrite the data file. But the write engine does have to read the original file to find out which row number the target record sits at.
So you're saving on write amplification but still doing some read work at ingestion time. The read cost, though, is manageable because the engine knows exactly which rows to skip without scanning the whole file.
Equality deletes are even faster to write. Instead of looking up row positions, you just record the column values of the records to delete, like customer_id = 12345. The write engine doesn't need to read anything at all. It just appends this condition to a delete file and keeps moving.
But here's the problem: at read time, the query engine has to scan through the entire base file and continuously evaluate every single row against those deletion predicates. For large files with many equality delete files accumulated, that's genuinely expensive. If you're using equality deletes heavily, compact aggressively, this is non-negotiable.
The bigger issue is that both mechanisms can generate a "small file problem" over time. Frequent deletions produce numerous tiny delete files scattered across storage. The query engine must parse multiple delete files for each read scan, and position delete files can develop "dangling deletes" pointing to records already excluded from active snapshots. This degrades performance even beyond the merge overhead.
The Apache Iceberg v3 specification addresses both of these limitations with something fundamentally better.
Deletion Vectors: The Modern Standard That Changes Everything
Both Apache Iceberg v3 and Delta Lake have moved toward Deletion Vectors as their preferred MoR implementation, and it's a significant architectural improvement over the scattered delete-file approach.

Instead of maintaining separate delete files pointing back to rows in base files, a deletion vector stores a compact bitmap alongside the base data file itself. The bitmap encodes which row positions are deleted using Roaring Bitmaps, a highly compressed binary structure that can be loaded directly into memory and evaluated using fast bitwise operations. This is fundamentally different from joining multiple fragmented files at read time.
The critical design rule is "one deletion vector per base file." Under this constraint, there's no accumulation of scattered, fragmented delete metadata. Each base Parquet file has exactly one companion deletion vector. This eliminates the multi-file join overhead that made classic MoR reads increasingly slow as delete files accumulated.
When you run a DELETE, UPDATE, or MERGE on a Delta Lake table with deletion vectors enabled, here's what actually happens step by step:
- Step 1: The engine identifies the target records in the affected Parquet files.
- Step 2: It writes their physical row positions as a compressed Roaring Bitmap into a tiny .bin companion file alongside the original Parquet file.
- Step 3: The original Parquet file is left completely untouched, no rewrite, no I/O on the base data.
- Step 4: For updates specifically, the old record is soft-deleted in the bitmap, and the new version is written to a separate small Parquet file. This avoids rewriting unchanged rows in the original file, dramatically reducing write amplification.
Enabling deletion vectors requires upgrading the table's protocol to Reader Version 3 and Writer Version 7. That protocol change is absolutely worth making for any update-heavy workload.
| Attribute | Iceberg v2 Delete Files | Iceberg v3 Deletion Vectors | Delta Lake Deletion Vectors |
|---|---|---|---|
| Storage format | Scattered Avro/Parquet files | Compressed .puffin sidecar files | Separate .bin companion files |
| Internal encoding | Explicit lists of positions or values | Roaring Bitmaps | Roaring Bitmaps |
| Write overhead | Fast but generates high file count | Minimal — enforces one DV per file | Minimal — avoids full file rewrites |
| Read-time engine load | High — multi-file joins and parses | Low — bitmaps loaded directly into memory | Low — skips marked row offsets |
| Compaction requirements | Scheduled compaction required | Write-time enforcement reduces need | Manual or automated OPTIMIZE |
Section takeaway: Deletion vectors are a fundamentally better MoR implementation. Compact, co-located, evaluated with fast bitwise operations, and governed by a strict "one DV per file" rule that prevents fragmentation. For any update-heavy workload on Iceberg or Delta Lake, this is the mechanism to adopt.
Compaction: The Hidden Control Plane of Lakehouse Reliability
Okay, so here's something that most articles get deeply wrong. They treat compaction as background maintenance, like periodically vacuuming your office. Nice to do, but not really architectural.
That framing is dangerously incorrect.
Compaction is the mechanism that makes MoR architectures survivable over time. Without it, read amplification compounds, storage fragments into thousands of tiny files, query planners slow down under metadata overhead, and your "fast ingestion" pipeline produces a table that nobody can query efficiently.
Researchers call this "reliability lag", the system looks excellent initially, then quietly degrades over months as compaction debt accumulates.

Minor vs Major Compaction
There are two levels of compaction and they serve different purposes.
Minor compaction consolidates small files (typically 1 MB to 10 MB) into larger, standardized ones (128 MB to 1 GB) without changing the logical sort order or data layout. It's fast, cheap, and primarily solves the small-file problem, preventing metadata planning overhead from ballooning.
Minor compaction consolidates small files (typically 1 MB to 10 MB) into larger, standardized ones (128 MB to 1 GB) without changing the logical sort order or data layout. It's fast, cheap, and primarily solves the small-file problem, preventing metadata planning overhead from ballooning.
Major compaction rewrites data files completely. It applies clustering, multi-dimensional sorting, schema evolution alignment, and physically purges deleted records from base files. This is the operation that drives post-compaction read performance back to CoW parity.
Apache Hudi Compaction Strategies
Hudi gives architects several configurable trigger strategies to determine when compaction runs. The NUM_COMMITS strategy triggers compaction after N delta commits have completed. TIME_ELAPSED schedules compaction after a configured number of seconds.
NUM_OR_TIME triggers on whichever condition is met first, this is usually the most practical default for streaming pipelines because it handles both traffic spikes and quiet periods gracefully.
Hudi also supports asynchronous compaction, which decouples maintenance from ingestion entirely. Rather than blocking write operations while compaction executes, async compaction lets the write pipeline continue uninterrupted.
For streaming workloads especially, the ability to run Hudi Streamer in continuous mode, where scheduling is inline and execution runs on a parallel thread, is a critical capability.
Apache Iceberg Compaction
In Iceberg, compaction runs via the rewrite_data_files Spark procedure and supports three core strategies. Bin-pack consolidates small files without altering sort order, fast, cheap, no data shuffles. Sort rewrites files while physically sorting records by specified columns, improving range queries and join performance.
Z-Order organizes data using a multidimensional clustering algorithm across multiple columns, enabling query engines to skip large amounts of irrelevant data using min/max file statistics, the most powerful strategy, but also the most compute-intensive.
One critical tuning principle: always define threshold gateways when calling rewrite_data_files. Specify a minimum file count and minimum file size before compaction triggers. Running compaction on already-healthy files wastes compute cycles and creates unnecessary metadata churn, a problem that compounds on large tables.
Delta Lake Auto-Compaction
Delta Lake handles compaction through its OPTIMIZE command. It can be configured to run automatically via Auto Compaction, which evaluates partition health synchronously after every write. If a partition exceeds a file-count threshold, Delta triggers a mini-OPTIMIZE to consolidate newly written fragments before committing. The key parameters are minNumFiles (default 50) and maxFileSize (default 128 MB).
Worth noting: the open-source Delta community identified a bug where already-compacted files were incorrectly counted toward the minNumFiles threshold, causing Auto Compaction to trigger on every single write as the table grew, creating heavy unnecessary write overhead.
This is a good reminder to stay current with patch releases and verify your compaction trigger behavior on production-scale data.
Section takeaway: Compaction is not optional maintenance, it's the primary mechanism that prevents MoR architectures from accumulating operational debt. Design your compaction policy before you design your ingestion pipeline, not after.
The Layered Architecture Strategy: Matching Storage to Data Flow
So here's a framework that ties everything together. The most effective lakehouse architectures don't pick one strategy platform-wide, they match the storage strategy to the characteristics of each layer in the medallion architecture.
🥉 Bronze Layer
Ingestion
High-volume CDC streams, streaming ingestion, frequent updates
Reduces compute spend up to 60%
🥈 Silver Layer
Refinement
Filtered, validated, enriched data. Mixed read/write patterns
Gate compaction on file-count thresholds
🥇 Gold Layer
Consumption
BI dashboards, interactive analytics, ML feature serving
Z-Order or Liquid Clustering for fast scans
The Bronze layer is where CoW most visibly fails. Applying a CoW approach to high-volume CDC ingestion causes continuous massive cluster utilization as files are repeatedly rewritten. Migrating to MoR here, using Hudi MoR tables or Delta Lake with deletion vectors, can cut compute spend by up to 60%, writing delta logs instead of rewriting entire base files.
At the Gold layer, you need the opposite. BI dashboards and interactive analytics require low-latency reads, and those queries can't tolerate merge overhead. Either use CoW tables here, or run aggressive major compaction (with Z-Ordering or Liquid Clustering) on MoR tables to ensure all changes are pre-materialized into optimized columnar files before your consumers hit them.
GDPR, Compliance, and the Soft Delete Problem
Here's a topic that doesn't get nearly enough attention, especially from teams operating in regulated industries. Under GDPR and similar regulations, organizations are legally required to physically delete Personally Identifiable Information (PII) upon a valid erasure request.

The thing is, a standard MoR delete operation doesn't actually remove data. It creates a deletion vector or delete file that tells the engine to ignore certain rows. The original Parquet file still contains the PII in full. If anyone runs a time-travel query against a historical snapshot, they can bypass the soft-delete metadata entirely and read the original records. That's not just a compliance gap, it's a regulatory liability.
Step-by-step hard-delete workflow in Delta Lake:
- Step 1: Run REORG TABLE ... APPLY (PURGE) to physically rewrite the affected Parquet files, removing the soft-deleted records from the actual data. This ensures the current data files are clean.
- Step 2: Run VACUUM with a short retention window, as low as 0 hours for immediate compliance, to permanently purge the historical physical files from object storage. This ensures historical versions are eliminated and time-travel queries can no longer surface the deleted PII.
Both steps are required. The first step cleans current files. The second eliminates historical access paths. Skipping either one leaves PII reachable through snapshot history.
For Iceberg, equivalent operations use the rewrite_data_files procedure combined with expire_snapshots. The same two-step logic applies.
Section takeaway: Soft deletes are not GDPR-compliant. Any MoR architecture handling PII needs an explicit hard-delete workflow that rewrites affected data files and exposes historical snapshots. Design this before your first GDPR request arrives.
Multi-Engine Interoperability: The Reality of Platform Compatibility
One thing that regularly trips up teams working in mixed-engine environments: not all query engines support all advanced storage features. This is especially visible in Microsoft Fabric, where deletion vectors, liquid clustering, and V-Order writing have uneven support across the compute stack.

For example: Python notebooks using delta-rs or the deltalake libraries cannot read tables with deletion vectors enabled at all. Fabric Spark Runtime 1.1 doesn't support deletion vectors. Pipelines connectors don't support deletion vectors. If you enable deletion vectors to speed up your ingestion pipeline and your data science team uses Python notebooks for feature engineering, those notebooks will fail silently or throw compatibility errors.
The workaround is straightforward but needs to be planned: use PySpark notebooks as a fallback for any consumer that needs deletion-vector-enabled tables. But the important point is that you need to audit your engine ecosystem before enabling advanced features, not after.
More broadly, the open table format ecosystem, while designed for interoperability, is converging toward platform coupling through metadata semantics rather than file formats. Delta Lake remains heavily Spark-centric, Hudi often favors streaming-heavy ecosystems, and Iceberg increasingly dominates multi-engine governance scenarios. Design for interoperability proactively.
The Migration Path: How to Switch from CoW to MoR (Without Breaking Production)
If you’ve realized your "simple" CoW deployment is actually bleeding compute budget, you don't have to live with it. Migrating an existing production table from CoW to MoR is a standard operational procedure, but it requires a disciplined approach to avoid data loss or schema mismatches.

This is not a "toggle" switch; it is a metadata evolution. Here is the 3-step checklist to safely migrate your tables:
Step 1: Audit and Prepare the Target Environment
Before you change the storage mode, verify that your read-engine ecosystem can handle the change. As noted, older versions of Delta Lake or specific Spark runtimes may fail when encountering deletion vectors or merge-on-read metadata.
- Action: Run a test workload in a staging environment using your production query engines (Trino, Presto, Spark, or BI tools) to ensure they can correctly resolve the MoR delta logs or bitmaps.
Step 2: Perform an "In-Place" Conversion
Most modern lakehouse formats support a transition without requiring a full table rewrite.
- In Apache Iceberg: You can update the write.format.default and write.delete.mode table properties. Existing data remains in its current format; only new writes will follow the MoR pattern.
- In Delta Lake: You enable deletion vectors at the table level using the ALTER TABLE ... SET TBLPROPERTIES command (specifically for protocol versions 3/7).
- Crucial: Do not try to convert all historical data at once. Let the table naturally adopt the new format as you continue to ingest data.
Step 3: Schedule the "Cleanup" Compaction
The moment you switch to MoR, your table becomes a hybrid of legacy CoW files and new MoR delta fragments. To restore query performance and ensure all data is eventually materialized into the most efficient format, schedule an immediate OPTIMIZE (Delta) or rewrite_data_files (Iceberg) job.
- Action: Set this as a one-time "catch-up" job to consolidate the legacy files, then transition to your standard, frequency-gated compaction policy defined in the previous section.
Section takeaway: Migration is an evolution, not a rip-and-replace. By transitioning the write mode and following up with a major compaction, you can convert an expensive, bloated table into an efficient, performant asset with zero downtime.
Common Mistakes Data Engineers Actually Make
So let's talk about the stuff people genuinely get wrong in production. These aren't theoretical edge cases.

Mistake 1: Choosing a storage strategy before defining SLAs
The most common error. Teams pick CoW or MoR based on a blog recommendation without first asking: how fresh does this data need to be? How many queries hit this table per hour? What's the acceptable read latency? Those answers determine the right strategy, not generic advice from an architecture post.
Mistake 2: Treating MoR as a "set it and forget it" choice
MoR without compaction is not a strategy. It's a slow-motion performance degradation that takes months to fully manifest. Design your compaction policy before deployment, not after your dashboards start slowing down.
Mistake 3: Assuming BI tools handle delta merges gracefully
Many BI tools and SQL engines have limited or no support for on-the-fly delta merging. If your downstream consumers can't handle MoR overhead efficiently, your "optimized ingestion pipeline" is creating a hidden tax for your analysts. Test with your actual query engines before committing architecture-wide.
Mistake 4: Ignoring compaction frequency for equality deletes
If you're using Iceberg v2 equality deletes, you need to compact aggressively. The read cost is severe because the engine must scan entire files and evaluate every row against deletion predicates. Without frequent compaction, these accumulate into a major performance bottleneck.
Mistake 5: Using CoW for high-frequency CDC ingestion
If you're ingesting Change Data Capture events from a transactional database, where records update many times per hour, CoW generates enormous write amplification. Rewriting 500 GB of base Parquet data every ingest cycle when you could write 20 GB of delta logs is simply wasting compute.
Mistake 6: Enabling deletion vectors without an engine compatibility audit
Deletion vectors require protocol upgrades and not all engines support them. Enabling this feature without checking your full tool stack can break downstream consumers in ways that are hard to debug.
Decision Framework: How to Actually Choose
Okay, let's put this together into a practical framework. Three questions get you to the right answer most of the time.
🧭 Storage Strategy Selector
Answer the three questions to get a tailored recommendation.
Before and After: The Real Impact of Getting This Right

Before (mismatched strategy):
A retail data team runs a high-frequency CDC pipeline ingesting order updates into a CoW table. Every 15 minutes, the pipeline rewrites 500 GB of base Parquet files across hundreds of partitions. Cloud compute costs are climbing month over month.
Write latency spikes during peak ingestion windows. Engineers spend weekends firefighting stalled pipelines. The team assumes the problem is cluster sizing.
After (right strategy):
The same pipeline migrates to MoR with deletion vectors. The ingestion job now writes 20 GB of delta logs per cycle instead of rewriting 500 GB. Compute costs drop approximately 60%. Write latency falls from minutes to seconds.
An OPTIMIZE job runs every 4 hours to compact the delta logs and restore read performance. Dashboards remain fast. The team sizes clusters correctly because they're no longer paying for unnecessary rewrites.
That pattern is documented in real production deployments, including Shopee's migration of high-update ingest workloads to Hudi MoR tables for their e-commerce analytics platform.
Contrarian Take: "Simple" CoW Isn't Always Simpler
Here's a perspective you don't hear often. The mainstream advice frames CoW as the "safe default", clean reads, no merge complexity, easy to reason about. And for low-update workloads, that's genuinely true.

But for high-update workloads, CoW creates what's best described as economic unsustainability. Small updates force full-file rewrites. At scale, updating millions of records per hour in a 10 TB table, the compute and storage I/O costs compound nonlinearly.
Many teams operating "simple" CoW deployments quietly accumulate enormous cloud bills before they realize the problem is architectural, not operational. The simplicity is an illusion that only holds when update frequency is low.
Meanwhile, a well-governed MoR deployment with proper compaction scheduling, threshold gating, and deletion vector support delivers nearly identical read performance at a fraction of the write cost. The operational complexity of compaction management is real, but it's bounded and predictable, unlike the cost escalation of CoW under heavy update loads.
The deeper truth is this: both CoW and MoR eventually pay the reconciliation cost. CoW pays it at every write. MoR defers it to compaction time. The question isn't "which is simpler", it's "where can your system absorb the cost most efficiently?"
Conclusion
So let's bring this together. Copy-on-Write and Merge-on-Read aren't really competing strategies, they're complementary tools that belong in different parts of your architecture and serve different workload profiles.
CoW is excellent for read-heavy workloads, append-only streams, and tables that update infrequently. The write cost is real, but the read dividend is permanent and requires zero operational overhead to maintain.
MoR, especially with deletion vectors, is the right choice for high-update workloads, CDC pipelines, and streaming ingestion. But it demands compaction governance. Without a thoughtful compaction policy, MoR tables accumulate operational debt silently and degrade gradually over time. Compaction is not a maintenance task; it's part of the architecture.
The best data teams in 2026 aren't choosing one over the other. They're layering intelligently, MoR at the Bronze ingestion layer, hybrid at Silver, CoW or compacted MoR at Gold. And they're treating compaction not as an afterthought but as a core design decision made before the first byte is ingested.
Get the strategy right, and your data platform becomes faster, cheaper, and more reliable. Get it wrong, and you'll be debugging performance regressions and unexpected cloud bills for months while everyone assumes the problem is somewhere else.
Frequently Asked Questions
What is the difference between Copy-on-Write and Merge-on-Read?
Copy-on-Write rewrites the entire Parquet file whenever a record is updated or deleted, producing clean columnar files for fast reads but paying a high write cost. Merge-on-Read appends changes to separate delta log files or deletion vectors, keeping the original file untouched for fast writes but requiring the query engine to merge base files with change records at read time.
When should I use Merge-on-Read instead of Copy-on-Write?
Use MoR when your workload involves high-frequency updates, streaming ingestion, or Change Data Capture pipelines. MoR is especially valuable at the Bronze ingestion layer where records change frequently and write latency matters. For tables that are rarely updated or primarily serve BI dashboards, CoW is typically the better choice.
What are deletion vectors and how do they improve MoR?
Deletion vectors are compact Roaring Bitmaps stored alongside base Parquet files that mark which rows have been deleted. Unlike the scattered delete files in Iceberg v2 or classic MoR approaches, each base file has exactly one companion deletion vector. This enforces a "one DV per file" rule that prevents metadata fragmentation and allows the query engine to evaluate deleted rows using fast bitwise operations rather than joining multiple fragmented files.
Why is compaction so important for Merge-on-Read tables?
Without compaction, MoR tables accumulate delta logs, delete files, or deletion vectors over time. Each read must load and merge these alongside the base file, increasing read amplification as modifications pile up. After running compaction, the delta metadata is merged into clean base Parquet files and read performance becomes identical to CoW. Compaction is not optional — it's the mechanism that makes MoR architecturally sound over time.
What is the Write Amplification Factor (WAF) and why does it matter?
WAF is the ratio of physical bytes written to storage versus logical bytes modified. In CoW, updating a 1 KB record inside a 100 MB Parquet file forces a 100 MB write — a WAF of 100,000. For streaming CDC pipelines running many updates per hour, this write amplification generates enormous compute costs and storage I/O. MoR strategies like deletion vectors reduce WAF to near-zero by appending only the changed data.
Are MoR soft-deletes GDPR-compliant?
No. Standard MoR soft-deletes only mark records as logically deleted via deletion vectors or delete files — the original Parquet files still contain the PII. Time-travel queries can bypass the soft-delete metadata and access historical records. For GDPR compliance, you must implement a hard-delete workflow: in Delta Lake, this means running REORG TABLE ... APPLY (PURGE) followed by VACUUM with a short retention window. Equivalent steps exist in Iceberg using rewrite_data_files and expire_snapshots.
What is the difference between position deletes and equality deletes in Apache Iceberg?
Position deletes record the exact file path and row index of each deleted record, making reads manageable because the engine knows which rows to skip. Equality deletes record column values matching records to delete (like customer_id = 12345), making writes faster since no file reading is required at ingestion — but making reads expensive because the engine must scan entire files evaluating every row against deletion predicates. Iceberg v3 replaces both with deletion vectors stored as Roaring Bitmaps.
Can I mix CoW and MoR strategies in the same data platform?
Absolutely — and this is the recommended approach for mature lakehouse architectures. Use MoR at the Bronze ingestion layer for high-volume CDC and streaming workloads, hybrid MoR with compaction at the Silver refinement layer, and CoW or aggressively compacted MoR at the Gold consumption layer serving BI dashboards. In Apache Iceberg, you can even set different modes per operation type (writes, updates, merges) using table-level properties, giving you granular control within a single table.







[…] Read the Full Article → […]