
Most guides on Apache Iceberg spend pages explaining Parquet files and snapshot isolation. Then they mention the catalog in two sentences: “it tracks table names” and “REST is the modern approach.” Done. Next topic.
That is a problem. Because here’s the thing: the catalog is not a footnote. It is the most operationally consequential decision you will make in your entire lakehouse architecture. Get it wrong, and you end up with concurrent write failures, stale metadata, engine incompatibilities, and security gaps that no amount of clever Parquet tuning will fix.

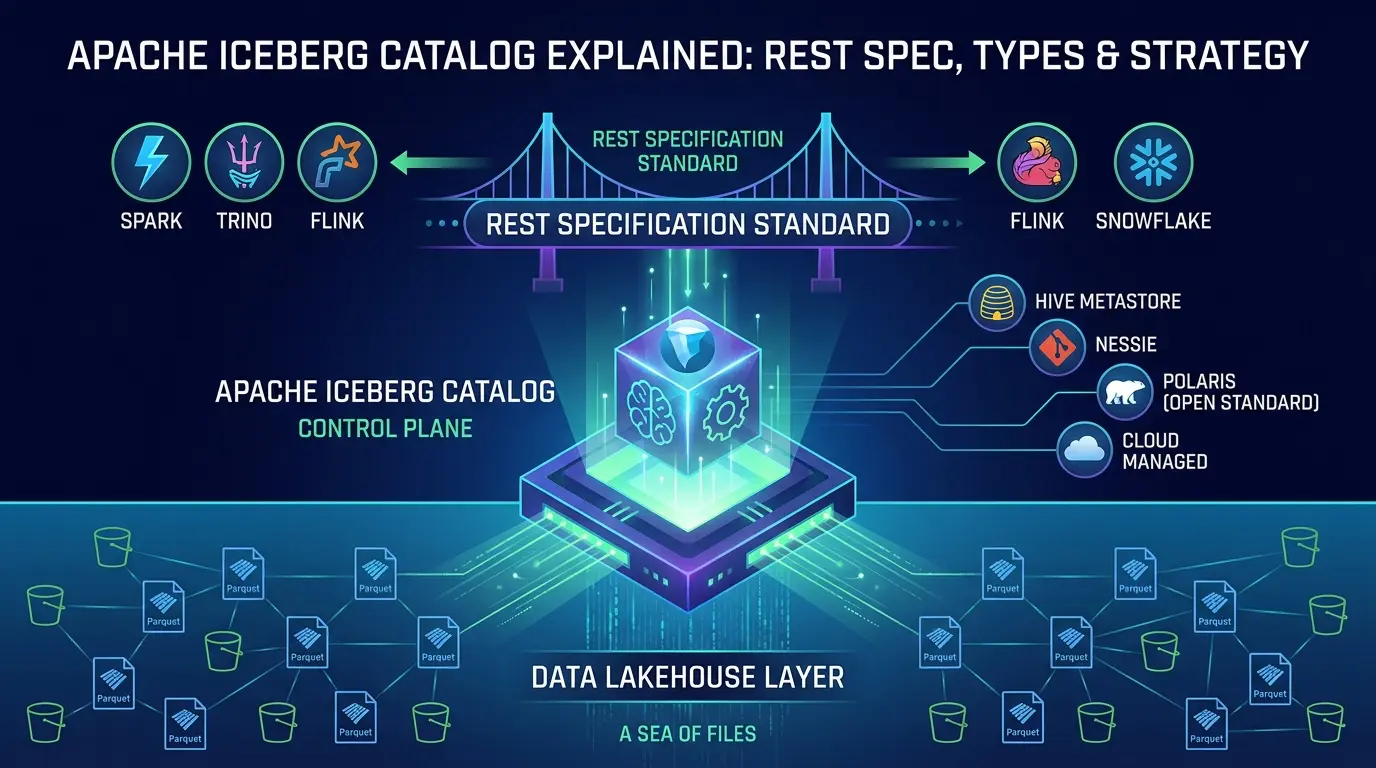
Think of it this way. Iceberg’s data layer is a sea of files. The metadata layer gives those files meaning. But neither layer knows who is looking, what has changed, or how to prevent two engines from overwriting each other’s work. That is what the catalog does. It is the control plane. And in 2026, as organizations run Spark, Flink, Trino, and Snowflake against the same tables simultaneously, the catalog has quietly become the most critical piece of infrastructure in the lakehouse stack.
This guide covers all of it: how the apache iceberg catalog actually works under the hood, why the REST specification matters beyond just “using HTTP,” how to choose among Hive Metastore, JDBC, Nessie, Polaris, Unity Catalog, and others, and what mistakes will hurt you in production. By the end, you will have a real mental model and a practical decision framework, not just a list of catalog names.
- The Iceberg catalog is a control plane, not just a name-to-location registry, it manages atomicity, concurrency, and commit coordination.
- The REST Catalog specification standardizes the interface between query engines and catalog services, enabling true multi-engine portability.
- File-based catalogs (Hadoop, Hive) are operationally fragile at scale; service-based REST catalogs are the production standard in 2026.
- Catalog choice drives governance, security, and write coordination, it is an architecture decision, not a product comparison.
- Apache Polaris graduated to a Top-Level Apache project in February 2026, cementing the open, vendor-neutral REST standard.
- Iceberg v4 will introduce relative paths and single-file commits, making tables more portable and real-time workloads more efficient.
What an Iceberg Catalog Actually Does
Let’s start with a scenario. You write a query: SELECT * FROM sales. Your engine, Spark, Trino, Dremio, whatever you are using, needs to find the data. Where does it look?

You are obviously not going to hard-code an S3 path into every query. That would be ridiculous and painful. And even if you tried, the path changes with every single snapshot anyway. Every time someone writes new data, Iceberg produces a new metadata file at a new path. Hard-coded paths would be out of date within minutes.
This is exactly where the catalog earns its existence. It maintains a simple but critical mapping: table name → current metadata file location. That is its first job.
Here’s what happens when you run that query. The engine asks the catalog: “Where is the sales table?” The catalog responds with the path to the current metadata JSON file in your object store. The engine reads that file, follows the tree through the manifest list, then individual manifest files, then arrives at the actual Parquet data files. The whole process is deterministic, consistent, and crucially, the same for every engine that queries through the same catalog.
But “pointer registry” undersells what the catalog is doing. Its second responsibility is ensuring atomicity. When a writer commits a new snapshot, whether it’s new data, a schema change, or a partition update, the catalog atomically swaps the metadata pointer from the old version to the new one. That single atomic swap is what gives you ACID consistency. Readers who started their query before the swap continue using the old snapshot. Readers who start after seeing the new one. Nobody sees a half-written table.
Third, and this is the part most guides skip: the catalog coordinates concurrent writes. If two engines try to commit to the same table at the same time, only one wins. The other sees a conflict and retries with the latest state. The catalog does not write data files, manifests, or manifest lists, your compute engine handles that. But it referees the commit process, ensuring no two writers stomp on each other’s work.
Tip: A useful mental model: the catalog never touches the actual data. It only manages the pointer to whoever does.
The Three-Layer Architecture You Need to Understand
Before diving into catalog types and REST, let’s get the architecture straight. Iceberg operates on three distinct layers, and the catalog owns the top one.
| Layer | Components | Format | What It Tracks |
|---|---|---|---|
| Catalog Layer | Catalog service or file | Service / pointer | Current metadata file path per table |
| Metadata Layer | metadata.json → Manifest List → Manifest Files | JSON / Avro | Schema, partitions, snapshots, file-level stats |
| Data Layer | Parquet / ORC / Avro data files | Columnar | Actual table rows |
The transition from one table state to the next follows a precise sequence. A writer produces new data files, then manifest files describing those data files, then a manifest list aggregating the manifests, and finally a new metadata JSON capturing everything. The catalog then performs one atomic swap: old metadata pointer → new metadata pointer.
That’s it. That one atomic operation is what gives Iceberg serializable isolation, the highest level of transactional consistency you can achieve. Readers are completely isolated from concurrent writes because they hold a reference to the snapshot that existed when their query started.
Understanding this sequence helps explain why the catalog matters so much. If the pointer swap isn’t atomic, you get partial reads. If the swap isn’t serialized, you get write-write conflicts. The entire ACID guarantee of Iceberg flows through that single catalog operation.
Section summary: The catalog is the sovereign of a three-layer hierarchy. It doesn’t touch your data, but every engine that does touch your data must go through it first.
How We Got Here: From Hive to REST
Here’s a quick history, because context matters for the choices you’ll face.
In the beginning, there was Apache Hive. Tables were directories. Partitions were subdirectories. You knew where your data was because you knew the folder structure. It worked for a while. And then it didn’t.

As data volumes scaled, the problems became severe. Recursive directory listing in S3 is slow. Very slow. A table with thousands of partitions meant thousands of API calls just to plan a query. Worse, Hive offered no isolation between readers and writers. A concurrent write could leave a reader seeing partial data mid-query. For a batch ETL running once a night, that was annoying but survivable. For production analytics or streaming workloads, it was a showstopper.
Apache Iceberg was designed by Ryan Blue and Dan Weeks at Netflix specifically to fix this. Instead of a directory-based state, Iceberg tracks every file in a metadata tree. Instead of listing directories, the query engine makes a single O(1) call to the catalog to find the metadata file, then traverses the tree to identify exactly which files it needs. No listing. No partial reads.
But even as Iceberg solved the storage problem, the catalog layer kept evolving through distinct phases.
Phase 1: File-Based Catalogs
The Hadoop Catalog used the file system itself, an atomic rename or overwrite of a version-hint.txt file, to track the current metadata pointer. Simple, no dependencies. But object storage systems like S3 don’t provide strong atomic rename semantics, so this model broke down under concurrency.
Phase 2: Service-Based Catalogs
Hive Metastore (HMS) moved pointer management into a relational database, providing real atomicity. Better. But HMS was built for directory-based Hive tables, used the Thrift protocol, and became an operational bottleneck at cloud scale. Teams started looking for alternatives.
Phase 3: Specialized Catalogs
AWS Glue, JDBC catalogs using PostgreSQL, and Project Nessie (which brought Git-like branching to tables) all emerged to solve specific problems. Each was useful. But each required the query engine to implement a specific connector. Spark needed a Glue connector. Trino needed its own. Python clients needed another. The combinatorial explosion of “engine × catalog” compatibility was becoming a real engineering tax.
Phase 4: REST Catalog Specification
Introduced in Iceberg 0.14.0, the REST spec defined a standard HTTP API that any engine in any language could use. Instead of building one connector per catalog type, engine authors build one REST client. Any catalog that implements the spec is immediately accessible to every engine that does the same. This is the current standard, and it is not going backward.
Catalog Types: The Honest Trade-Off Guide
Good news: you have options. The less good news: every option comes with real trade-offs. Here’s the honest version.
| Catalog Type | Atomic Commits | Multi-Engine | Multi-Table Txns | Cloud Agnostic | Best For |
|---|---|---|---|---|---|
| Hadoop Catalog | ⚠️ Weak (no S3 rename) | Limited | ❌ | HDFS only | Local dev, HDFS migration |
| Hive Metastore | ✅ Single-table | Moderate | ❌ | ✅ | Legacy Hadoop migration, batch ETL |
| JDBC Catalog | ✅ (DB-backed) | Moderate | Limited | ✅ | Teams with existing RDBMS expertise |
| AWS Glue | ✅ | AWS engines | Limited | ❌ (AWS-bound) | AWS-first organizations, managed ops |
| Nessie | ✅ | Good | ✅ | ✅ | Teams needing Git-like branching |
| Apache Polaris | ✅ | ✅ Full | ✅ | ✅ | Vendor-neutral multi-engine deployments |
| Unity Catalog | ✅ | ✅ + Delta | ✅ | Partial | Databricks-centric shops, Delta+Iceberg |
One thing the table above doesn’t capture: operational ownership. A JDBC catalog backed by PostgreSQL is simple to understand but puts you in charge of availability, scaling, and backups. A managed catalog like Polaris or AWS Glue offloads that operational burden, at the cost of flexibility or cloud lock-in respectively.
Hive Metastore is worth a specific callout here. It does not support atomic commits with multiple concurrent writers. For batch ETL jobs running on a schedule, that’s tolerable. For streaming workloads or any environment with multiple simultaneous writers, you will hit conflicts. This is not a future concern, it will bite you in production.
Section summary: Every catalog type makes a different trade-off between simplicity, atomicity, portability, and governance. The right choice depends on your engines, your team’s operational capacity, and your governance requirements, not brand recognition.
Real-World Case Study: Scaling Metadata Management
To understand the practical impact of choosing the right catalog, let’s look at a common scenario faced by data-intensive organizations.
A high-growth e-commerce platform was struggling with their data lake performance. They were initially utilizing a traditional Hive Metastore to manage their Apache Iceberg tables. As their data volume grew, they encountered two major bottlenecks:
- Metadata Latency: Frequent write operations from Apache Spark and Flink caused severe contention on the Hive Metastore, leading to significant delays in data availability.
- Consistency Issues: In a multi-engine environment (where both Spark and Trino were accessing the same tables), they frequently faced locking conflicts, causing jobs to fail during peak hours.
The Solution:
The team migrated to an Apache Iceberg REST Catalog. By decoupling the catalog service from the underlying file system and leveraging the REST API for atomic commits, they achieved:
- Improved Throughput: By utilizing the REST Catalog’s lightweight, API-based communication, they eliminated the overhead associated with the traditional Hive-style locking mechanism.
- Enhanced Reliability: The shift to a REST-based architecture provided better concurrency control, allowing multiple engines to read and write to the same tables without the “stale metadata” issues that plagued their previous setup.
Key Takeaway:
While a Hive Catalog is sufficient for small, static datasets, migrating to a REST Catalog is a strategic move for any team operating at scale. It shifts the burden of metadata management from a rigid, file-based system to a flexible, API-driven service that is designed to handle the concurrency demands of modern data architectures.
The REST Catalog Specification: What It Actually Standardizes
Here is a commonly misunderstood point: REST is not the story. Standardized interface semantics are the story.

Before the REST spec, every query engine needed to implement a specific Java class (or Python library, or Go package) for every catalog it wanted to support. Spark needed a HiveCatalog class. Trino needed its own. Python clients needed theirs. Every new catalog meant a new round of engine-specific implementation work. As the Apache Iceberg documentation shows, this connector matrix was genuinely painful to maintain across a growing ecosystem.
The REST Catalog spec solved this by defining a common HTTP/JSON contract. Any engine that speaks REST can talk to any catalog that implements the spec. It doesn’t matter if the engine is written in Java, Python, Rust, C++, or Go. It doesn’t matter if the catalog backend is PostgreSQL, a cloud-managed service, or a custom store. As long as both sides follow the spec, they interoperate. That’s the real win.
Here are the core endpoints defined by the specification:
| Endpoint | Method + Route | What It Does |
|---|---|---|
| Configuration | GET /v1/config | Capability discovery — catalog tells engine what features it supports |
| Table Load | GET /v1/{prefix}/namespaces/{ns}/tables/{table} | Returns current metadata location and schema to the client |
| Table Commit | POST /v1/{prefix}/namespaces/{ns}/tables/{table} | Atomically swaps the metadata pointer for a new snapshot |
| Multi-Table Commit | POST /v1/transactions/commit | Atomic success or failure across multiple related tables |
| Register Table | POST /v1/{prefix}/namespaces/{ns}/register | Adopts an existing metadata.json into the catalog (key for migrations) |
The Configuration Endpoint Is Smarter Than It Looks
The GET /v1/config call is how every REST client starts its session. The catalog server uses this response to push runtime configuration to the engine. It can send:
- Overrides, organizational policies the client cannot ignore (like which S3 bucket is the warehouse)
- Defaults, baseline settings that simplify client configuration
- Supported endpoints, a list of features the server actually implements
That last point matters a lot. Not every REST catalog implements every endpoint. The configuration response lets the client know, at runtime, exactly what the server can do. This makes the spec genuinely forward-compatible. When Iceberg adds new features, like support for views or v4 metadata structures, the server can advertise that capability through /v1/config, and compatible clients immediately take advantage of it without any engine upgrades.
Diff-Based Commits: Why REST Handles Conflicts Better
One of the less-discussed advantages of the REST spec is how it handles commit conflicts. In traditional catalog implementations, a commit replaces the entire metadata file atomically. If two writers both try to commit at the same moment, one succeeds and the other fails, period.
The REST spec’s commit model is diff-based. Instead of replacing everything, the client sends a description of what changed: “I want to add these data files” or “I want to update this schema field.” The server can then evaluate whether that specific change conflicts with what another writer just committed. In many cases, changes that would cause a blanket conflict under the old model can actually be safely merged by the server. This is a meaningful reduction in retry overhead for high-concurrency workloads.
Security, Auth, and Access Delegation
Let’s talk about the parts of the catalog that tend to get glossed over until something goes wrong: authentication and storage access.

The REST spec adopts OAuth2 as the standard for authentication. The engine authenticates with an identity provider (Okta, AWS Cognito, Azure AD) to receive a bearer token, which it includes in every catalog request. The catalog inspects the token’s claims to determine what the user can do, SELECT on this namespace, INSERT on that table, no access to the other one.
By 2025–2026, the best practice shifted toward fully external Identity Providers rather than relying on an OAuth endpoint inside the catalog itself. This separation of concerns is exactly right: your catalog should manage metadata, not run your organization’s identity infrastructure.
The Harder Problem: Giving Engines Access to Storage
Here’s a challenge that comes up constantly in production: your compute engine needs to read Parquet files from S3. How do you grant that access without handing out long-lived, high-privilege storage keys?
The REST spec defines two approaches, and both are worth understanding.
| Feature | Credential Vending | Remote Signing |
|---|---|---|
| How it works | Catalog issues short-lived STS tokens scoped to the table’s bucket/prefix | Catalog signs each storage request; client uses pre-signed URLs |
| Credentials leave server | Yes (short-lived, scoped) | No — never |
| Storage throughput | Native (client → storage directly) | High (via pre-signed URLs) |
| Security posture | Strong (auto-expiring, scoped) | Maximum (zero credential exposure) |
| Best for | Most production environments | Zero-trust, strict compliance environments |
Credential vending works like a hotel key card: you check in (load the table), you get a temporary key scoped only to your room (bucket prefix), and it expires when you check out. Remote signing is more like a vault where the security guard unlocks the door for you but never hands you the key. Both are far superior to distributing long-lived IAM keys to every compute cluster.
This delegation model is what allows the storage layer to remain a simple “bit bucket”, just S3 or GCS, while the catalog acts as the intelligent policy enforcement point for who can access what and when.
Choosing the Right Catalog: A Practical Decision Framework
Here is the part most articles skip: a real decision framework. Not a list of catalog names. An actual way to think through the choice.

The research team at Apache Iceberg’s project governance has consistently emphasized three dimensions that matter most in catalog selection. Think of them as Pointer, Policy, and Protocol.
- Pointer: Does the catalog reliably manage atomic pointer swaps under your concurrency requirements? File-based catalogs fail here at scale. Service-based catalogs generally succeed.
- Policy: Does the catalog support the governance requirements your organization needs? Fine-grained access control, lineage tracking, multi-tenant namespaces? Some catalogs offer this natively; others delegate to external systems.
- Protocol: How do your engines communicate with the catalog? Is the REST spec fully supported? Are there engine-specific connectors you’ll need to maintain?
Answer the questions below to get a starting recommendation.
The Contrarian Take: More Catalogs Is Usually a Problem
Here is an insight that almost no guide will tell you: running multiple catalogs simultaneously is almost always a liability, not a feature.
Teams often end up with multiple catalogs through organic growth, one catalog for Iceberg tables, another for Delta, a third inherited from a legacy Hive migration. Each catalog holds a different view of table state. When engines read from different catalogs, you get metadata drift. A table that was compacted in Catalog A shows stale file lists in Catalog B. A schema change committed through one path doesn’t propagate to another.
The operational discipline here is simple: consolidate your write path to a single catalog. Use one authoritative source of truth for table state. If you need to expose data to multiple engines or platforms, those should all be reading from the same catalog, not from separate ones.
Common Mistakes That Will Hurt You in Production
These are real errors, not theoretical ones.

Mistake 1: Choosing a catalog by brand familiarity, not engine compatibility
Teams pick AWS Glue because “we’re on AWS” without checking whether their specific version of Spark or Trino supports Glue’s Iceberg commit model correctly. Check the feature matrix for your exact engine versions before committing.
Mistake 2: Assuming REST support equals full feature parity
The REST spec defines a minimum contract. Implementations vary significantly. A catalog can claim REST support while only implementing table load and basic commit, no multi-table transactions, no credential vending, no configuration endpoint. As Lisa Cao from DataStrato noted in a 2025 community presentation, you need to verify which specific endpoints your chosen catalog actually supports.
Mistake 3: Treating Hive Metastore as a production Iceberg catalog for streaming
HMS works for a batch. For anything with concurrent writers or streaming ingestion, you will see committed conflicts. This is a documented limitation, not an edge case.
Mistake 4: Skipping the auth design until late in the project
Security in a multi-engine environment is genuinely complex. Who can commit to which namespace? How are storage credentials scoped? These decisions affect every table operation. Design them upfront, not as an afterthought after your first production incident.
Mistake 5: Not testing catalog failure modes
What happens to your running queries when the catalog is temporarily unavailable? Do your engines fail gracefully? Can they complete reads using cached metadata? Test this before you find out in production.
Note: The best catalog is often not the most feature-rich one, it’s the one that your specific set of engines can safely and consistently share, with well-defined failure behavior.
Snapshot Accumulation and Why Maintenance Matters
Every write operation creates a new snapshot. That’s the whole point of Iceberg’s time-travel capability. But without maintenance, snapshots accumulate indefinitely. Metadata grows. Storage costs climb. Query planning slows down as the manifest tree deepens.
Here’s a simple way to think about storage growth from snapshots:
Retained Files = Retention Days × Daily Commits × Avg Files Per Commit
// Without expiration policy, this grows unbounded
// Target: Retention Days = 7–30 for most workloads
Estimate how many metadata file references accumulate over your retention window.
The catalog is central to all three major maintenance operations:
- Snapshot Expiration removes snapshots older than your retention policy. Daily or weekly for active tables.
- Data Compaction rewrites many small files into fewer large ones (target 100MB–1GB per file). This is how you solve the “small file problem” from streaming ingestion.
- Orphan File Cleanup deletes files that were written to storage but never committed to a snapshot (e.g., from failed jobs). Monthly is typical.
Compaction deserves special mention. Because it is a standard Iceberg transaction, it is fully transparent to concurrent readers. The compaction job reads small files, writes large ones, commits a new snapshot. Readers continue using the previous snapshot until the commit finalizes. Zero downtime, zero inconsistency.
| Maintenance Task | Recommended Frequency | Primary Benefit | Risk if Skipped |
|---|---|---|---|
| Snapshot Expiration | Daily / Weekly | Controls metadata growth and storage costs | Exponential metadata bloat, slower planning |
| Data Compaction | Continuous / Scheduled | Fixes small file problem, improves scan speed | Degrading query performance over time |
| Statistics Refresh | Post-write / Scheduled | Keeps optimizer statistics accurate | Poor query plans, full table scans |
| Orphan File Cleanup | Monthly | Reclaims storage from failed writes | Wasted storage, cost accumulation |
Migrating from Hive: The Practical Path
Transitioning from Hive to Iceberg is a metadata operation, not a data movement exercise. That matters a lot, it means zero data duplication and minimal downtime in most cases.

The most common approach is the migrate procedure. It reads existing Hive partition information, generates Iceberg manifests and manifest lists from that data, and updates the catalog pointer. The Parquet files themselves don’t move. A table with terabytes of data can migrate in minutes because you’re only rewriting metadata.
For mission-critical tables where even a brief write pause is unacceptable, you can use a “dual-write” strategy: the ingestion pipeline writes to both the Hive and Iceberg tables simultaneously during a transition window. Once all downstream readers are on the new format, the Hive table is decommissioned.
For cross-catalog migrations, say, moving from self-managed HMS to Google BigLake’s Iceberg REST catalog, the register_table API is your tool. It creates a pointer in the destination catalog to the existing metadata.json on object storage. No data moves. You just tell the new catalog where to look.
One critical gotcha: the LOCATION property in the new namespace must exactly match the physical storage path of your data. URI mismatches, even minor ones like missing trailing slashes, or s3:// vs s3a:// scheme differences, will cause read failures. Always validate this before migrating any production table.
The 2026 Landscape: Polaris, Unity, and Federation
By 2026, the industry has largely converged. The REST specification won. The question now is not whether to use REST, but which REST-compliant catalog to run and how to manage federation across platforms.

The most significant milestone was Apache Polaris graduating to a Top-Level Project at the Apache Software Foundation on February 18, 2026. Polaris was originally donated by Snowflake, but its TLP status makes it genuinely vendor-neutral. It supports simultaneous access from Snowflake, Spark, Flink, and Trino, no proprietary extensions, no capability gates for non-Snowflake engines. Its RBAC model enforces consistent access control across all engines at the metadata level, so the same permission policy applies whether you’re querying through SQL on Spark or streaming through Flink.
Databricks Unity Catalog took a parallel but different approach. Its “Compatibility Mode” automatically exposes managed Delta Lake tables through read-only Iceberg REST endpoints. In 2026, Databricks extended this with write support for externally managed Iceberg tables on Azure, which is significant, it means organizations can now use Unity Catalog as a governance layer over Iceberg tables they fully own, without data duplication or format conversion.
Google Cloud went with “bidirectional interoperability.” BigLake’s Iceberg REST catalog lets BigQuery act as a full Iceberg catalog, while also supporting “Catalog Federation“, managing and querying tables that live in external REST catalogs through the BigQuery API. The result is a unified view across multi-cloud environments, which is increasingly the reality for large organizations.
What this means practically: for the first time, you can have Spark on AWS, BigQuery on GCP, and Trino on-premise all reading and writing to the same Iceberg tables through a standardized catalog interface, with consistent governance and without vendor lock-in. That was not really possible three years ago.
What’s Coming: Iceberg v4 and the Next Generation
The community is actively developing the v4 specification, focused on two persistent pain points.
Single-File Commits will consolidate all metadata changes into one file per commit, instead of the current sequence of manifest list → manifests → metadata JSON. For high-frequency streaming workloads, this I/O reduction translates directly into write throughput improvements and less coordination overhead for concurrent writers.
Relative Path Support is arguably the more impactful change for operations teams. Currently, Iceberg stores absolute S3/GCS URIs inside manifest files. If you copy a table to a new region for disaster recovery, you have to rewrite every metadata file to point to the new location. With relative paths, files are referenced relative to a base URI defined in the table metadata. Copying a table becomes a true copy, no metadata rewrite required.
| Spec Version | Major Innovation | Primary Impact |
|---|---|---|
| v1 | Analytic table fundamentals | Snapshot isolation, O(1) query planning |
| v2 | Row-level deletes | UPDATE, DELETE, and MERGE support |
| v3 | Deletion vectors and VARIANT type | Faster MoR operations, semi-structured data |
| v4 | Single-file commits and relative paths | Real-time write throughput, full regional portability |
The v4 Adaptive Metadata Tree proposal is also worth watching. By moving toward a Parquet-based metadata format, engines will be able to prune metadata the same way they prune data, loading only the column statistics they need for query planning rather than reading entire manifest lists. For tables with millions of files, this could substantially reduce query planning overhead.
Conclusion
The Iceberg catalog started life as a simple pointer registry. A table name, a metadata file path, done. But the demands of real production environments, concurrent writers, multi-engine access, governance requirements, global data movement, have steadily expanded that role into something much more significant.
Today, the catalog is the control plane for your entire open lakehouse. It enforces atomicity, coordinates writes, manages storage access, and provides the consistent metadata state that every engine depends on. The REST specification formalized this expanded role into a standard that any engine in any language can use, and the ecosystem has responded, Polaris, Unity Catalog, Lakekeeper, and Gravitino all implement it. The result is a genuinely open, portable, multi-engine data architecture that was largely theoretical just a few years ago.
For your immediate decisions: choose a catalog based on your engine requirements, governance needs, and operational capacity, not brand recognition. Plan your maintenance strategy upfront. Design your auth model before your first table goes into production. And if you are building a greenfield today, start with REST.
The “sea of files” in object storage has always had the potential to behave like a reliable, unified database. The catalog is what actually makes that promise real.







[…] Read the Full Article → […]
[…] Read the Full Article → […]