
Authorization is the step that happens right after authentication. Once someone logs in, once the system knows who they are, the next question kicks in immediately: what are they actually allowed to do?
That question sounds deceptively simple. In practice, it’s one of the hardest problems in software design.
A startup can get away with four roles and a permission table. Give that same system six months, three enterprise customers, a microservices migration, and some AI-powered features, and suddenly that clean permission table has become a sprawling mess of exceptions, one-off overrides, and tribal knowledge that nobody fully understands anymore. Sound familiar?
")
This guide covers how authorization really works, starting from the foundational mechanics of RBAC, building through ABAC and ReBAC, explaining Google’s Zanzibar model and why it changed everything, then covering policy engines, microservices enforcement patterns, and the new challenges that AI agents are introducing right now.
Let’s look at each layer clearly, understand where it fits, and figure out how to combine them without creating a system that eventually collapses under its own complexity.
- Authorization controls what an authenticated user can do, and broken authorization is the #1 web application security risk (OWASP 2021–2025).
- RBAC, ABAC, and ReBAC are not competing alternatives, they are complementary layers you stack on top of each other.
- RBAC fails organizationally before it fails technically, role explosion and authorization debt are the real threats.
- Google’s Zanzibar processes 10 million+ authorization checks per second with <10ms p95 latency, its design is the blueprint for modern ReBAC systems.
- The “New Enemy Problem” is a real distributed systems race condition, ZedTokens are the causal consistency solution.
- AWS Cedar runs up to 80.8× faster than Rego and supports formal mathematical verification of policies in CI/CD pipelines.
- Without deterministic pre-action authorization, AI agents are successfully manipulated 74.6% of the time. With it: 0%.
What Authorization Really Does (And Why It’s Different From Authentication)
Authorization is the process of determining what actions an authenticated identity is permitted to perform on specific resources within a system. It occurs after authentication and is responsible for enforcing access boundaries, not verifying identity.
")
Think of it this way. Authentication is the bouncer checking your ID at the door. Authorization is the map of which rooms inside the building you’re actually allowed to enter, and what you can do once you’re in them.
Let’s look at GitHub as a concrete, real-world example. When you access a repository, GitHub isn’t just checking whether you’re logged in. It’s evaluating a layered set of questions:
- Can this user push code to this branch?
- Can they create pull requests?
- Can they manage repository settings?
- Can they delete the repository entirely?
These are all authorization decisions. Each happens independently of the login step. And as you can see, even a simple code-hosting platform needs a surprisingly nuanced permission model.
The stakes are high. According to OWASP’s Web Application Security Top Ten, broken access control has been ranked the number one web application security risk for multiple consecutive years, ahead of injection attacks, cryptographic failures, and everything else. That’s not a coincidence. Most systems are reasonably good at authentication. Authorization is where things quietly fall apart.
So understanding this topic well isn’t academic exercise, it directly shapes how secure, scalable, and auditable your systems actually are.
Section Summary: Authorization controls what authenticated users can do. It’s distinct from authentication, and broken authorization is the leading cause of modern application security failures.
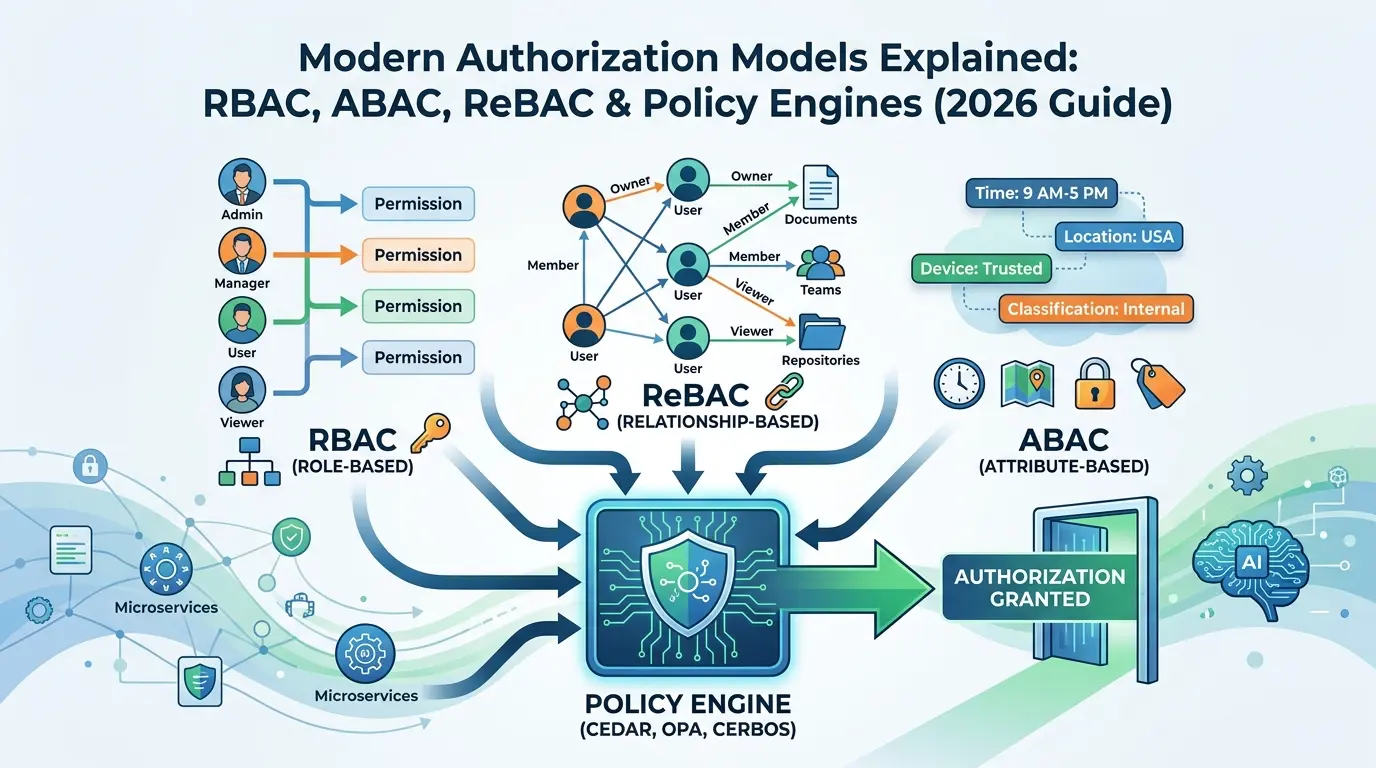
A Mental Map: How the Three Core Models Relate
Before diving deep into each model, it helps to establish a clear mental map. Modern authorization frameworks aren’t random approaches, they form a nested hierarchy, almost like layers of a Russian doll.
- ABAC (Attribute-Based Access Control) is the outermost and most expressive layer. Nearly any access control rule can be mathematically expressed using attributes.
- ReBAC (Relationship-Based Access Control) sits inside that, it’s a specialized form of ABAC that uses graph relationships between entities as the primary control mechanism.
- RBAC (Role-Based Access Control) sits at the center, the simplest, most pre-computed form of all, where relationships are static and pre-defined.
This hierarchy matters because these models aren’t competing alternatives that you choose between. They’re complementary layers. The most robust production systems use all three together, each handling the type of access decision it’s best suited for.
| Model | Core Question | Best For | Main Weakness | Real-World Example |
|---|---|---|---|---|
| RBAC | What role does this user have? | Stable orgs, clear job functions | Role explosion at scale | GitHub repo permissions |
| ABAC | Do the current conditions permit this? | Dynamic, context-aware rules | Policy governance complexity | Time-restricted data access |
| ReBAC | Does a valid relationship path exist? | Collaborative, hierarchical systems | Distributed graph consistency | Google Drive sharing |
| PBAC | Does the evaluated policy permit this? | Microservices, compliance-heavy systems | Policy authoring expertise required | Kubernetes admission control |
| ACL | Is this user on this resource’s permission list? | Fine-grained per-resource control | Hard to scale to millions of objects | Google Docs share settings |
RBAC: The Foundation That Powers Most Systems
Role-Based Access Control (RBAC) is an authorization model where permissions are assigned to roles, such as “admin,” “editor,” or “viewer”, and users are then assigned to those roles rather than receiving permissions directly.
")
RBAC is the most widely deployed authorization model in software today, and for good reason. It maps naturally to how organizations actually work. People have job functions. Job functions have responsibilities. Responsibilities define what systems people need access to.
Let’s look at how this works in a content management system:
- Admin: can create, read, update, and delete all content; can manage other users
- Editor: can create, read, and update content; cannot delete or manage users
- Viewer: can only read published content
When Alice joins as an editor, you don’t individually grant her 47 separate permissions. You assign her the Editor role, and she inherits exactly the rights that role carries. When she’s promoted to admin, you update her role assignment, one change, instant effect across the whole system.
Role Hierarchies: Inheritance Up the Chain
Real organizations have layered structures, and RBAC supports this through role hierarchies. A senior role can inherit all the permissions of a junior role and add additional capabilities.
For example, in an accounting system:
- Accounting Clerk can view financial records and create expense reports
- Accounting Supervisor inherits all Clerk permissions, plus the ability to approve transactions and manage team members
This prevents duplicating common permissions across dozens of role definitions. You update one role, and the change propagates to everyone holding it automatically.
Where RBAC Works Best
RBAC excels in specific conditions, and it’s worth being clear about exactly when to use it:
- Stable organizational structure with well-defined job functions
- Environments where auditability matters more than flexibility
- Regulated industries (healthcare, finance, government) with fixed compliance requirements
- Internal tools, admin dashboards, and applications with a manageable number of distinct user types
The catch? Those conditions describe fewer and fewer modern SaaS applications.
Section Summary: RBAC maps users to roles and roles to permissions, making access management scalable across large organizations. It’s ideal in stable, structured environments where job functions are clearly defined.
Where RBAC Breaks Down: Role Explosion and Authorization Debt
Here’s a scenario most engineering teams will recognize.
A product launches with four clean roles: Admin, Manager, User, Viewer. Three months later, there’s a special “ReadOnlyAdmin” for auditors. Then a “RegionalManager” for European users. Then “SupportTier1” and “SupportTier2” because those apparently need different access.
By month six, someone needs temporary incident access, so there’s an “IncidentResponder_Temp” role. A year in, there are 47 roles, nobody is sure which ones are still active, and deleting any of them feels too risky to try.
This is role explosion, and it’s how most RBAC systems degrade.
The structural problem is fundamental. Pure RBAC has no mechanism to express conditional logic. Every unique combination of access requirements demands its own role. Want to restrict a feature to business hours? New role. Want to limit access by geographic region? New role. Want to grant access based on resource ownership? New role.
Here’s the counterintuitive insight most articles miss: RBAC doesn’t fail computationally, it fails organizationally.The security model itself is sound. But it assumes three things that modern SaaS applications violate constantly:
- Stable organizational structure
- Bounded, well-understood permission sets
- Low relational complexity between entities
When those assumptions break, role explosion follows. Role explosion leads to cognitive overload. Cognitive overload leads to over-broad fallback roles. Over-broad fallback roles lead to privilege creep. Privilege creep leads to insider risk escalation.
")
Authorization Debt: The Risk Nobody Measures
Authorization debt is a concept that doesn’t get nearly enough attention. Like technical debt, authorization policies accumulate historical assumptions, old org structures, deprecated teams, inherited exceptions, emergency overrides that were never cleaned up.
Unlike code debt, authorization debt directly affects compliance, insider risk, and incident attribution. Organizations often genuinely cannot answer the question: Why does this user still have this access?
The contrarian insight worth highlighting: more granular permissions can actually reduce practical security. When the system becomes complex enough that humans stop fully modeling it, audits become approximation exercises, emergency overrides proliferate, and a system designed to be secure becomes effectively unauditable.
The best authorization system isn’t the most flexible one, it’s the one your team can still fully understand a year later.
Section Summary: RBAC fails organizationally before it fails technically. Role explosion and authorization debt are the real long-term threats. Granularity beyond human cognitive limits reduces, not increases, practical security.
ABAC: Adding Context to Access Decisions
Let’s look at what happens when you need access control that goes beyond job titles.
Attribute-Based Access Control evaluates requests by examining attributes, properties attached to the user, the resource being accessed, or the environment at the time of the request. Instead of asking “what role does this user have?”, ABAC asks “do the current conditions permit this access?”
A typical ABAC policy might look like this:
“Allow access IF the user’s department equals ‘HR’ AND the resource classification equals ‘internal’ AND the current time is between 09:00 and 18:00”
As you can see, this is far more expressive than a static role assignment. You can factor in three categories of attributes simultaneously:
- User attributes: department, seniority, employment status, geographic location, clearance level
- Resource attributes: classification, owner, sensitivity, data category, creation date
- Environmental attributes: time of day, device type, network trust level, current threat signals
This expressiveness is what makes ABAC the natural choice for zero-trust security postures. Zero trust means “never trust, always verify”, access decisions need real-time context, not just the identity of who’s asking, but the circumstances of the request.
")
The Governance Challenge
ABAC’s power comes with a real cost: governance complexity. Each new attribute creates new combinations of conditions to reason about. Policies can conflict. Rules can produce unexpected outcomes in edge cases. Without centralized management, ABAC logic fragments across services and becomes difficult to audit with confidence.
The practical recommendation is to use ABAC to refine RBAC, not replace it entirely. RBAC establishes the baseline structure and job-function access. ABAC adds the contextual conditions, the “only during business hours,” “only from trusted networks,” “only for resources you own” refinements. This hybrid approach is what mature production systems actually run.
Section Summary: ABAC evaluates user, resource, and environmental attributes for context-aware access. It’s best used as a refinement layer on top of RBAC, not as a wholesale replacement.
ReBAC: When Relationships Define Access
Now let’s explore the model that powers Google Drive, modern document editors, and most collaborative SaaS applications.
Relationship-Based Access Control models authorization as a directed graph. Nodes are entities, users, groups, organizations, documents, folders, repositories. Edges are relationships, “Alice owns this document,” “Bob is a member of the Finance team,” “this folder belongs to that project.”
Permissions are determined by traversing the graph to find a valid path between a subject and a resource.
Think about how Google Drive actually works. You share a folder with a colleague. That colleague can now access every document inside that folder, and every sub-folder inside it.
If they share a sub-folder with a third person, that person inherits access to documents within that scope. Access flows through the relationship graph naturally, without requiring you to manually enumerate permissions for every single file.
There are three fundamental relationship types in ReBAC:
- Actor-Actor: Relationships between identity objects. An incident response team inherits the combined permissions of nested security subgroups.
- Resource-Resource: Structural linkages between data objects. Access to a parent resource cascades down to all child objects.
- Actor-Resource: Binds an identity to a specific resource without regard for job role. A user who submitted an expense report gets viewing rights to that specific report, not all reports in the system.
Google Zanzibar: The Blueprint for Modern Authorization
The most influential authorization system ever built is Google’s Zanzibar. As described in Google’s original Zanzibar research publication, it powers Google Drive, YouTube, Gmail, Google Maps, and many other services simultaneously.
The scale is almost incomprehensible:
- Over 2 trillion access control lists maintained
- More than 10 million authorization checks per second
- 95th-percentile latency under 10 milliseconds
- Global availability exceeding 99.999%
Zanzibar models permissions using normalized relationship tuples. Understanding this structure is key to understanding modern authorization engines.
Zanzibar Relationship Tuple Format
object # relation @ subject
relation = viewer // the permission type
subject = user:alice // individual user or group:relation
This tuple means: Alice has viewer access to document:quarterly-report. Subject can also be a userset like group:finance#member, which means “all members of the finance group.”
These tuples allow complex nested structures to expand recursively. When you compose an email in Gmail and attach a Drive document, Gmail silently queries the Zanzibar service to verify that every email recipient has a valid relationship path to that document. All in under 10 milliseconds.
Visualize how access flows through a relationship chain. Enter subject, relation, and object to build a tuple.
Section Summary: ReBAC models access as graph traversal, ideal for collaborative systems with nested hierarchies. Google Zanzibar is the gold standard, it handles trillions of ACLs at under 10ms latency.
The New Enemy Problem: Distributed Consistency in Authorization
Here’s a distributed systems challenge that most authorization guides don’t cover in enough depth, but every production system eventually needs to solve.
")
When you distribute authorization data across globally replicated databases to minimize latency, you create a dangerous race condition that Zanzibar’s authors formally named the New Enemy Problem.
Let’s walk through exactly how this happens, step by step:
- Kara revokes Lex’s access to a shared folder. The deletion is committed to the primary authorization store.
- Replication lag means this deletion hasn’t propagated to all database replicas worldwide yet.
- Kara uploads a sensitive document to the folder, confident the revocation is secured.
- Lex immediately requests access — his request routes to a stale replica that still holds the old relationship tuple.
- The stale replica grants Lex access to the newly created sensitive content. He becomes the “new enemy.”
This vulnerability appears in any system relying on JWT tokens for authorization decisions, because revoked permissions remain active until the token expires. A 24-hour JWT gives a revoked user up to 24 hours of lingering access after you’ve removed them.
ZedTokens: The Causal Consistency Solution
Zanzibar and its open-source successors solve this elegantly through causal consistency tokens, called Zookies in Zanzibar and ZedTokens in SpiceDB.
When a permission change is written (like revoking a user), the authorization service returns a compact token representing the exact logical timestamp of that transaction. The application stores this token alongside the resource content in its database.
When any future access check runs on that resource, the application passes the stored token to the authorization engine. The engine verifies that the replica processing the request is at least as fresh as that token timestamp. Stale replicas wait or route to a fresher one.
The result: it’s technically possible to experience a brief “false negative” where a newly added collaborator has a slight delay before accessing a file. But you completely prevent the security-critical “false positive” of a revoked user accessing new content. That’s the right tradeoff.
| SpiceDB Consistency Level | How It Works | Typical Latency | Security Trade-off | Best Use Case |
|---|---|---|---|---|
| Minimize Latency | Uses nearest local cache, ignores global timestamps | <1ms | ⚠ Vulnerable to New Enemy | UI rendering, non-sensitive listings |
| At Least As Fresh | Ensures data is at least as fresh as the ZedToken | 2–5ms | ✅ Prevents New Enemy | Collaborative apps, post-revocation checks |
| At Exact Snapshot | Evaluates against the exact point-in-time of the ZedToken | 3–8ms | ✅ Point-in-time accurate | Paginating large result sets |
| Fully Consistent | Bypasses all caches, queries primary database cluster | ~12ms+ | ✅ Maximum consistency | Compliance-critical access decisions |
One critical note for teams using CockroachDB as a backend: setting fully_consistent does not guarantee read-after-write consistency due to distributed clock skew between nodes (up to 500ms). To guarantee read-after-write in CockroachDB, always use at_least_as_fresh paired with a valid ZedToken.
Section Summary: The New Enemy Problem is a real race condition in distributed authorization stores. ZedTokens enforce causal consistency, preventing revoked users from accessing new content, at only 2–5ms additional latency.
Policy Engines: OPA, Cedar, Cerbos, and OpenFGA
So far, we’ve talked about models for thinking about authorization. Now let’s look at the engines that evaluate those models at runtime, the dedicated services that your applications call to get an allow or deny decision.
This is where authorization becomes truly decoupled from application code. Instead of writing if (user.role === ‘admin’ && resource.ownerId === user.id) scattered across dozens of microservices, you express policies centrally and let a dedicated engine make the call. This is what NIST’s Zero Trust Architecture guidelines (SP 800-207) describe as the Policy Decision Point pattern.
")
There are four primary policy engines in modern cloud-native systems:
Open Policy Agent (OPA) uses the Rego policy language, a Datalog-inspired declarative query engine. It’s the CNCF standard for cloud-native policy, deeply integrated with Kubernetes admission control. The learning curve is steep (30–40 hours to become proficient), but it’s extremely flexible for expressing arbitrary JSON-based logic.
AWS Cedar uses an explicit permit/forbid model with schema-driven validation. Performance benchmarks show Cedar executing 28.7x to 35.2x faster than OpenFGA and up to 80.8x faster than Rego. It runs in O(n) time relative to the number of applicable policies. Per Cedar’s official policy language documentation, it’s designed as a pure mathematical function with no side effects, which enables something extraordinary.
Cerbos uses YAML combined with Google’s Common Expression Language (CEL). It has a very gentle learning curve (5–10 hours) and is resource-centric by design. It’s an excellent entry point for teams new to externalized authorization.
OpenFGA is a CNCF sandbox project designed specifically for fine-grained authorization following the Zanzibar model. It’s excellent for relationship-based scenarios but less suited for heavy real-time contextual evaluation.
Formal Verification: Why Cedar Changes the Game for Security-Critical Systems
One capability that sets Cedar apart for compliance-heavy or AI-powered applications is formal mathematical verification, the ability to prove that your authorization policies behave correctly before they ever hit production.
Cedar is designed as a pure function. This enables formal verification using SMT (Satisfiability Modulo Theories) solvers. In CI/CD pipelines, the Cedar Analysis toolkit can mathematically check your policies for:
- Shadowed permits: rules that are completely redundant because a broader policy already covers the same request space
- Impossible conditions: policies with mutually exclusive constraints that can never be satisfied in practice
- Complete denials: specific actions that are fully blocked under all circumstances, potentially unintentionally
- Equivalent policy sets: mathematical proof that two different policy configurations produce the exact same set of allowed requests
This formal analyzability is why Amazon uses Cedar to secure agentic workflows in Amazon Bedrock AgentCore. When an LLM can hallucinate or be manipulated through prompt injection, a formally verified authorization layer is the safety net that prevents bad outputs from becoming security breaches.
Section Summary: Policy engines decouple authorization from application code. Cedar offers the best performance and formal verification; OPA offers the most flexibility; Cerbos has the gentlest learning curve; OpenFGA is best for Zanzibar-style relationship models.
Authorization in Microservices: Where to Put the Decision Point
Let’s look at a very common architectural mistake that teams make when moving to microservices.
The mistake is placing all authorization logic at the API gateway. It feels elegant, one chokepoint, one check, done. But this violates the defense-in-depth principle and becomes unmanageable as services multiply. The gateway becomes a crowded collection of unrelated business rules that no single team owns. And when it fails, it takes authorization down for everything simultaneously.
")
According to OWASP’s Microservices Security Cheat Sheet, the recommended pattern is Centralized Policy with Embedded PDP, and understanding why requires understanding what PDPs and PEPs actually are.
- PDP (Policy Decision Point): The component that evaluates “should this access be allowed?”, your policy engine
- PEP (Policy Enforcement Point): The component that actually enforces the decision, your application code that receives the allow/deny
There are three main ways to arrange these in a microservices architecture. Let’s look at each one clearly:
The Centralized with Embedded PDP pattern gives you the best of both worlds: centralized policy governance without centralized runtime dependency. Policies sync from one source of truth, but each service evaluates them locally.
Token Validation: Online vs. Offline
Related to this is a decision about how services validate incoming identity tokens:
- Online validation: The service calls the Identity Provider for every request to verify the token. Slow (adds network latency to every call), but immediately detects revoked credentials.
- Offline validation: The service downloads the IdP’s public cryptographic keys and validates token signatures locally. Fast and resilient, but blind to revocations until the token expires.
Most production systems use offline validation for performance, combined with short expiry windows (15–60 minutes) to limit the post-revocation window. High-security paths (payment processing, admin actions) use online validation selectively.
Section Summary: Use Centralized Policy with Embedded PDP. Define policies once, distribute asynchronously, evaluate locally. Avoid API gateway as the sole authorization enforcement point.
Common Authorization Mistakes (And How to Avoid Them)
Let’s be direct about the errors that repeatedly show up in production systems.
")
Mistake 1: Hardcoding authorization logic inside microservice code
Every service develops its own checks. Policies drift. A security change requires touching dozens of codebases simultaneously. Use an external policy engine or embedded PDP instead.
Mistake 2: Treating RBAC as sufficient for multi-tenant SaaS
RBAC alone cannot naturally enforce tenant boundaries. Developers end up writing hardcoded tenant validation checks inside every service. This is exactly the fragmentation that creates data leakage bugs that take weeks to track down.
Mistake 3: Ignoring the New Enemy Problem
Building a globally distributed system and assuming authorization data is always consistent is dangerous. Without ZedToken-style causal consistency, every access revocation has a window of vulnerability.
Mistake 4: Using JWTs as the authorization source of truth
JWTs carry identity claims, not authorization decisions. Embedding granular permissions inside JWTs creates network bloat (reportedly approaching 1MB in highly granular systems), cache pressure, and revocation blindness. Use JWTs for identity; call a policy engine for authorization.
Mistake 5: Over-engineering toward maximum granularity
This is the counterintuitive one. Finer-grained permissions feel more secure. But there’s a cognitive limit to what your team can reason about. When authorization becomes too complex to mentally model, audits become incomplete approximations, emergency overrides proliferate, and practical security decreases.
Mistake 6: Deploying new policies directly to production blocking mode
Always start new authorization rules in audit mode first. Log what would have been blocked without actually blocking it. Monitor for false positives. Then promote to enforcement mode. This prevents security improvements from surprising users and creating escalations.
Mistake 7: Treating authorization as a solved problem after initial setup
Authorization systems accumulate debt. Roles get orphaned. Exceptions persist indefinitely. Permissions outgrow their original scope. Regular access reviews, every 3–6 months minimum, are not optional; they’re how you prevent privilege creep from quietly escalating insider risk.
Before and After: What Modern Authorization Looks Like in Practice
Let’s make the transformation concrete with a realistic scenario.
")
Before: A typical B2B SaaS platform at 18 months
The platform launched with four clean roles. Eighteen months later, there are 31 roles. Nobody remembers what “SupportAgent_Tier1_ReadOnly_Legacy” actually does, but everyone is too nervous to delete it. Three different microservices each implement their own tenant isolation checks, inconsistently.
An enterprise customer reported occasionally seeing data from another tenant; tracing the bug took two weeks because authorization logic was scattered everywhere. Answering a compliance audit question (“who can access what and why?”) took three days of manual investigation.
After: A layered Policy-Based Authorization architecture
All authorization logic lives in one dedicated policy repository with version control, pull request reviews, and automated tests. RBAC defines baseline roles, Admin, Member, Support.
ABAC conditions enforce tenant isolation and time-of-day restrictions. ReBAC handles collaborative document sharing within tenants. Every authorization decision is logged with full context. New policies deploy in audit mode first, monitored against production traffic before enforcement activates. The same compliance audit question now takes minutes.
The difference isn’t just security posture. It’s operational clarity, faster incident response, faster onboarding of new services, and the organizational ability to confidently answer questions about who has access to what, and why.
GitOps for Authorization: Treating Policies Like Production Code
Modern authorization policies should be managed exactly like application code, version controlled, peer reviewed, tested in CI, and deployed through automated pipelines. This is the GitOps model applied to security.
")
Under a strict GitOps approach:
- All policies live in a dedicated Git repository, separate from application source code. Separation prevents tight coupling of the security lifecycle to deployment cycles and lets security teams review policy changes independently.
- Every change goes through a pull request with automated syntax validation and unit tests.
- New policies deploy in WARN mode first, they observe and log what they would have blocked without actually blocking anything.
- Once telemetry confirms zero false positives over a meaningful production traffic window, the policy promotes to ERROR/ENFORCE mode.
- GitOps operators (like Argo CD) reconcile the Git state with the active cluster automatically.
Policy classes in a CI/CD pipeline follow a four-category model:
- Validate: The gatekeeper. Rejects deployments that fail baseline security standards before any resource is created.
- Mutate: The auto-corrector. Automatically patches resource declarations to conform to corporate standards at admission time.
- Generate: The companion creator. Automatically instantiates secondary resources when primaries are created (e.g., generating a default-deny NetworkPolicy the moment a new Namespace appears).
- Audit: The reporter. Scans active systems against policy baselines and reports drift without blocking anything.
One architectural caution: GitOps operators like Argo CD hold high-level cluster administration rights. Deploy them in a dedicated management cluster isolated from the workloads they govern, enforce strict network microsegmentation, and require branch protection rules on policy repositories with mandatory security team review.
Authorization for AI Agents: The Frontier Most Systems Aren’t Ready For
This is where the discussion moves into territory most authorization guides don’t address yet, but need to.
")
AI agents are executing actions autonomously right now: browsing web pages, writing and running code, sending emails, modifying files, querying databases, and calling external APIs. They need permissions to do their work. But they also need hard, deterministic boundaries to prevent prompt injection attacks, hallucinations, and unintended access to sensitive systems.
The research data is clear and striking. Without deterministic pre-action authorization, adversarial users successfully manipulated autonomous AI agents 74.6% of the time. With restrictive deterministic authorization applied before each action, meaning the agent must pass an explicit authorization check before executing any tool call, that adversarial success rate dropped to 0% across 879 attempts. The performance overhead of this enforcement: 53ms median per check.
Model alignment, instructing the AI to “only do safe things”, is insufficient as a security control. It’s a probabilistic guardrail, not a deterministic boundary. Authorization needs to be enforced by a system external to the model itself, with the same rigor applied to human users.
The practical recommendation for teams building agentic systems:
- Assign each AI agent a unique, auditable identity (not a shared service account)
- Apply the principle of least privilege, grant only the minimum permissions needed for the specific workflow
- Enforce authorization before execution, not after the fact
- Log every action with full context for audit trails
- Use Cedar or another formally verifiable policy engine for the authorization decisions
This is an emerging frontier, and the authorization tooling is maturing quickly. Teams that build this into their agent architecture now will have a significant security and compliance advantage as regulation in this area accelerates.
Strategic Recommendations: Building a Layered Authorization System
Let’s bring everything together into a practical implementation roadmap.
")
Layer 1: Start with RBAC
Define roles around real job functions, not organizational exceptions. Keep the role count low, aim for under 20 for most applications. Use role hierarchies to inherit permissions upward rather than duplicating them. Enforce separation of duties constraints from day one for high-risk function combinations.
Layer 2: Add contextual conditions with ABAC
Use attributes to handle the conditions RBAC can’t express: tenant isolation, time-based access, resource ownership, geographic restrictions, device trust level. Don’t replace your roles, refine them with conditions.
Layer 3: Model relationships for collaborative features
If your application involves shared documents, team hierarchies, or nested resource structures, use a ReBAC-style engine. For serious scale or strict read-after-write requirements, consider SpiceDB or OpenFGA as your authorization store.
Layer 4: Externalize policy decisions to a dedicated engine
Move authorization logic out of application code and into a Policy Decision Point. Choose based on your team’s needs and use case. Start with Cerbos if you want a fast adoption path. Use OPA for Kubernetes-heavy environments. Use Cedar for compliance-critical or AI-agent workflows requiring formal verification.
Layer 5: Enforce causal consistency
If your application has real-time sharing, revocations, or collaborative features, implement ZedToken-style consistency tokens to prevent the New Enemy Problem. Use at_least_as_fresh as your default consistency mode.
H3: Layer 6: Manage everything as code
Maintain a dedicated policy Git repository separate from application code. Run automated tests on every pull request. Deploy in audit mode before enforcement mode. Review and prune policies quarterly. Treat authorization debt with the same urgency as security vulnerabilities.
Conclusion: Authorization Is Infrastructure, Not an Afterthought
Authorization has quietly become one of the most complex disciplines in modern software engineering. It’s no longer a permission table sitting beside your users table. It’s a distributed system with consistency requirements, graph traversal algorithms, declarative policy languages, formal verification tooling, and increasingly, AI governance requirements.
The teams that get this right don’t pick one model and stick with it dogmatically. They layer RBAC for structural clarity, ABAC for contextual conditions, ReBAC for relationship-based access flows, and policy engines for governance, then manage the entire system as the critical infrastructure it actually is.
The goal isn’t the most flexible authorization system you can possibly build. The goal is the most understandable system that still meets your security requirements. Because an authorization model your team can no longer fully reason about is an authorization model that will eventually fail quietly, and expensive failures rarely announce themselves.
Start with roles. Add context. Model relationships when you need them. Externalize decisions early. Manage policies like code. Audit regularly.
That sequence is the path from a permission table to a production-grade authorization architecture, and it’s one of the highest-leverage investments any engineering team can make.
❓ Frequently Asked Questions About Authorization Models
What is the difference between authentication and authorization?
Authentication answers “who are you?” — it verifies identity through credentials, biometrics, or tokens. Authorization answers “what are you allowed to do?” — it controls access to resources and actions after identity is confirmed. You can have strong authentication and still have completely broken authorization. Most modern security failures involve the latter.
Is RBAC still relevant in 2026?
Yes — RBAC is the backbone of most authorization systems and will remain so. The argument isn’t that RBAC is obsolete; it’s that RBAC alone is insufficient for modern SaaS, collaborative applications, and zero-trust environments. RBAC provides the structural baseline. ABAC adds context. ReBAC adds relationships. All three together is what modern systems actually need.
How do you prevent role explosion in RBAC?
Five proven strategies: (1) Design roles around job functions, not system permissions. (2) Use ABAC conditions to handle exceptions instead of creating new roles. (3) Implement role hierarchies to share common permissions without duplication. (4) Assign role owners accountable for reviewing and maintaining each role. (5) Conduct quarterly access reviews to identify and retire unused or overlapping roles.
What is the New Enemy Problem in distributed authorization?
The New Enemy Problem is a race condition where a user whose access was revoked can still access newly created resources because their revocation hasn’t propagated to all database replicas. It occurs in globally distributed authorization stores due to replication lag. The solution is causal consistency tokens (ZedTokens in SpiceDB, Zookies in Zanzibar) that ensure authorization checks only evaluate against a replica that is at least as fresh as the last permission change for that resource.
When should I use ReBAC over RBAC?
Use ReBAC when access naturally flows through relationships rather than job functions. If your application has shared documents, nested folders, team hierarchies, project memberships, or any feature where “who you know” determines what you can see — ReBAC is the right model. Google Drive, GitHub, Notion, and Jira-style tools all use relationship-based access under the hood.
Should I use OPA or Cedar as my policy engine?
It depends on your context. Use OPA/Rego if you’re in a Kubernetes-heavy environment and need maximum flexibility to express arbitrary JSON-based policy logic. Use Cedar if you need the fastest possible performance, schema-driven validation, and the ability to formally verify policies mathematically in CI/CD — especially for compliance-critical systems or AI agentic workflows. Use Cerbos if your team is new to external authorization and needs a fast, readable starting point.
How do AI agents fit into authorization systems?
AI agents must be treated as first-class principals with scoped permissions, unique identities, and full audit trails — exactly like human users. Research shows that without deterministic pre-action authorization, adversarial manipulation of AI agents succeeds 74.6% of the time. With it, that drops to 0%. The key principle: authorization must be enforced externally to the model, not relying on prompt instructions or alignment alone.
What is policy-based access control (PBAC) and how does it differ from RBAC?
PBAC centralizes authorization logic into explicit, versioned, testable policies evaluated by a dedicated policy engine (like OPA or Cedar). Unlike RBAC, where access is determined by static role assignments, PBAC policies can incorporate roles, attributes, relationships, and environmental conditions simultaneously. PBAC doesn’t replace RBAC — it governs it, along with ABAC and ReBAC, into a unified, auditable decision framework.






